Team meetings
This week I had a lot of in-person team meetings (Volkswagen & BMW, Manufacturing and Enterprise) and a lot of talks. I also presented my Agentic AI and Konveyor AI Slides from last week and we’ve had several discussions. It’s always interesting when many Red Hatters come together and learn how different people in different positions see things from their perspectives.
OpenShift AI Proof of Concept
I’m participating in two proof of concepts from the manufacturing industry, both different for different reasons. One is an OpenShift PoC without GPUs (although GPUs are available in general) and is intended to explore the extent to which this might still make sense on a production line. The other is about replacing and standardizing existing ClearML workflows while avoiding vendor lock-in and deploy also on a production line on lower-performance computers. Both aim to be more independent in terms of deployment in the hyperscalers’ clouds, deploying their models both on-premises and across multiple clouds.
It’s a super interesting new topic for me. Although I’ve done several workshops on OpenShift AI, these will be my first two proofs of concept in that topic. Actually getting my hands dirty is a completely different experience than simply providing the theoretical foundation or demonstrating finished demos and benefits in use.
Monitor LLamastack & vLLMs in OpenShift
The topic of this week’s Developer UX Meetup was how to monitor a Llamastack and vLLMs in OpenShift with built in toolings. Here’s a link to the github repo
Luckily, it was very technical and nerdy; you saw a lot of code and were able to understand how things interact. I thought that was really good.
The goal of the exercise was to see exactly how long each query runs in the LLM, i.e., down to the depth where tokens are generated. It’s great for debugging and understanding generated content, as well as for implementing guardrails. Here’s a screenshot of the monitoring which was shown in Grafana Tempo:

Build and deploy a ModelCar container in OpenShift AI
KServe’s ModelCar is a capability that allows you to serve machine learning models directly from a container in OpenShift AI. It simplifies the process by enabling you to build a container image that contains your model files in a /models folder, which can then be deployed in an OpenShift cluster. This approach reduces the need for S3-compatible storage and streamlines model management in production environments.
Here’s a good blogpost that describes how to get started.
It outlines a build process using podman to create a container image that can be pushed to a container registry. The article also covers deploying a model server using the OpenShift AI dashboard, specifying necessary connection details and adjusting deployment timeouts. It concludes by summarizing the pros and cons of using ModelCar containers, emphasizing standardization and potential challenges.
Validated Pattern: Industrial Edge
At the MLOps Community of Practice Meetup, we discussed the Validated Pattern Industrial Edge:
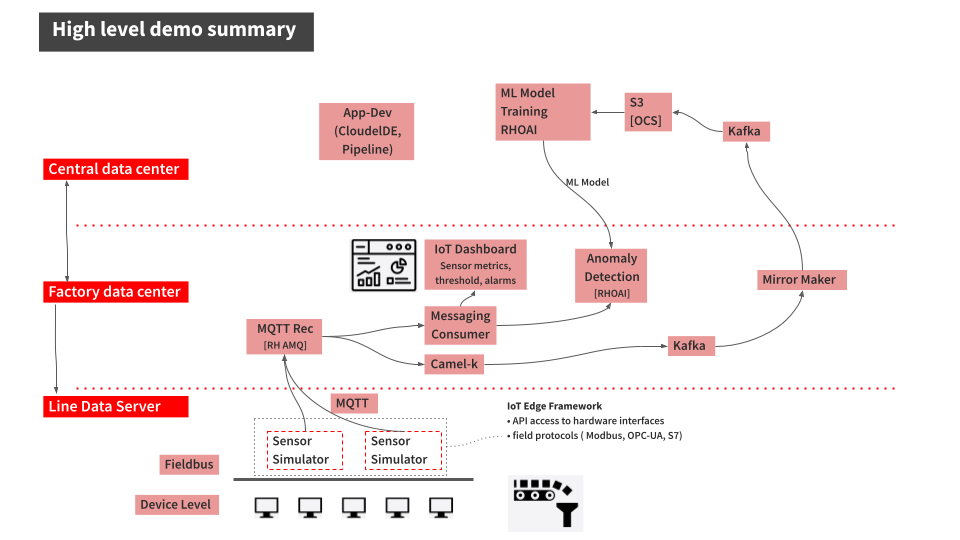
I’ve presented it several times to several clients and wanted to know what’s new. The project originated in the manufacturing vertical; specifically, it was about demonstrating how to use a (predictive) model in a manufacturing process using Red Hat technology. In addition to OpenShift AI and Kafka, the solution also includes Mirrormaker2, Camel, and Quarkus. A very nice demo that also takes into account the fact that production lines don’t have the greatest power available.
See here for more code or here for a detailed guide on how to get stared and what’s that all about.